What Led to This Post
First of all, it was that I needed a break. I've been working on ARs, doing some embedded Linux stuff, working on Skinned Scrollbars, and Uniscribe at the same time. So yesterday afternoon, I thought I'd like to take a little journey.
One of the patterns that has become kind of popular in VisualWorks of late is the "Properties Dictionary". There are some drawbacks to them, but one of advantages is they allow for a sort of "poor man's instance variable pool." Using them, one can store state by by name, in a structure that isn't quite as established as standard instance variables. Package's use them. Various parts of the RB use them. VisualPart's use it.
These dictionaries have a similar usage pattern. They tend to be smaller in size. Their primary usage tends to be at:(ifAbsent:) and at:put:, where the keys are usually someone constant. Or in other words, the majority of the time, at:put: is replacing an existing value, rather than adding a new slot to the dictionary.
Which led to a bigger question even. Even without worrying about the consistency of keys, what about small dictionaries in general?
Are small dictionaries that common?
Here's a bit of code we can use to get a view on that question:
histogram := Bag new.
Dictionary allInstancesDo: [:each | histogram add: each size].
IdentityDictionary allInstancesDo: [:each | histogram add: each size].
histogram
Exporting the data and playing with GoogleDocs a bit, we come up with this:
At least in my image, smaller dictionaries actually take up more space then the large dictionaries (area under the red curve is greater than that of the blue curve). And obviously, there's a lot more of them than the larger dictionaries.
Another kind of analysis (which I did not do) would be to look at what the access rates of dictionaries are as a function of their size. In other words. Are we sending messages as often to the big dictionaries as we are the small ones?
Some Points of History
Seeing that optimizing smaller dictionaries is an interesting pursuit, is not a new idea. The original Refactoring engine sported a specialized RBSmallDictionary. It exploited the fact that for its use cases, the sizes were usually only one or two. The overhead of hashing, probing, etc wasn't really worth it for these usually-one-element dictionaries. Having their own, also allowed them have a specialized removeAll that was very fast.
When Steve Dahl added CompactDictionary for UCA, it looked close enough to RBSmallDictionary, that dropped RBSmallDictionary in favor of it. Both implementations are basically linear search dictionaries.
Over the last few releases, there have been a number of changes to hashing algorithms and Dictionary implementations in VisualWorks, primary instigated by Andres Valloud, which have changed the value of CompactDictionary/RBSmallDictionary as well. Take a look at the speed boost of CompactDictionary versus IdentityDictionary when sending #at: with Symbols as keys. It's basically a draw at this point. The #at:put: story shows a moderate benefit for using a CompactDictionary over an IdentityDictionary when your size is 4 or less.
It's basically a draw at this point. The #at:put: story shows a moderate benefit for using a CompactDictionary over an IdentityDictionary when your size is 4 or less.
I'm told, that in the way-back-machine, VSE played games with optimizing small dictionaries. I don't have any more details than that though, and would love it if someone could speak truth to that rumor.
#at:(put:) Considered Harmful
The conventional wisdom to gain better dictionary performance is to work on hash algorithms. Make them faster. Make them separate better. Certainly that work will yield results. I think Andres's work has shown commendable efforts in those areas.
Sometimes we have to step out of our box and think about the problem from a different view point though. All of the improvements in hash algorithms ignore another important aspect of Smalltalk optimization. At the end of the day, all of this work on Dictionary will still result in the low level primitives for at: and at:put: running. Not the dictionary methods, but the one that is like the one found on array
anArray at: 4 put: anObjectThe problem with this is that Smalltalk VM's want to be very safe. A bit of work is done every time the at:(put:) primitives fire. First, the VM wants to make sure you passed it an integer. And then it wants to convert your Smalltalk integer representation into a machine one. And then it wants to make sure that number is greater than one, and less than the current size of the variable sized receiver. That means it has to go fetch the current size first. And if that's all OK, then it wants to figure out what the real offset is from the header of the object. So it has fetch how many fixed fields it has first, and then add that to the offset. And now it can finally assign a pointer in the objects body to the object being stored at that slot. Oh yeah, there's a check in there to determine if size was really big, then the body of the object is in LargeSpace. You do this kind of work for every single at: and at:put: you do, whether indirectly or indirectly. A higher level Dictioanry>>at:put: will have to first compute a hash, then candidate insertion point, and then probe via a low level at: to see if it has a collision or existing value, and then eventually do an at:put: when it gets everything straightened out. And there's the overhead of just sending the message.
How much slower is indexed access than fixed variable access? It's easy to write a little snippet that will give us a hint
| point array index |
fixed := 3 @ 4.
array := Array new: 1000.
index := '888' asNumber.
[100000000 timesRepeat: [array at: index]] timeToRun asMicroseconds
asFloat / [100000000 timesRepeat: [point y]] timeToRun asMicrosecondsI get around 60% slower for VW 7.9 builds. But this is only a hint. It's not correct really. Because the point y expression doesn't just measure fixed var access, but also a message send. So in reality, the disparity is farther. I noodled about this for a while, I'm curious if anyone has a better way of comparing the two access methods in a truer measure. Basically, what we want to compare is the speed of the byte code to "push a known index" vs the speed of the #at: send.
A Dictionary with Fixed Slots
This is something I've wanted to try for a while. A linked list implementation where each link exposes a dictionary like interface. I tried to come up with a good name for this thing, and then gave up and called it Chain. It's actually implemented with two polymorphic classes. Here's what a Chain with two elements looks like
Chain and EmptyChain end up having the same basic set of methods. Both inherit from Collection. Most of the methods are a fun exercise in recursive programming. For example, here's the two #at:ifPresent: implementations
at: aKey ifPresent: aBlock
^key = aKey
ifTrue: [aBlock value: value]
ifFalse: [nextLink at: aKey ifPresent: aBlock]and
at: aKey ifPresent: aBlock
^nilIn fact most of the EmptyChain methods do simple things like raise an error, return nil, return a copy, or do nothing. The two that are kind of fun are #at:put: and #removeKey:.
Chain #at:put:
The Chain implementation of #at:put: is simple:
at: aKey put: anObject
aKey = key
ifTrue: [value := anObject]
ifFalse: [nextLink at: aKey put: anObject].
^anObjectThis will handle the cases where we already have aKey in our Chain and just want to update the value stored at that key. When we have a new key though, it will make it through to the EmptyChain implementation:
at: aKey put: anObject
| newLink |
newLink := Chain basicNew.
newLink setKey: aKey value: anObject next: newLink.
self become: newLinkThere's a at least two interesting things going on here. The firs is that we use basicNew to instantiate a new Chain link. The reason is that Chain new redirects to EmptyChain new by default. Since a "new Chain" should be an empty one.
Since an EmptyChain link doesn't know who references it, we use a #become: to insert the new link in the chain. We could implement these two classes as a doubly linked list, but that requires more space, more management, and VisualWorks #become: is very fast. The trick in using the #become: is that we initially set the newLink's nextLink var to point back to itself. Before we do the #become:, we have another link pointing to the EmptyChain, or perhaps it really is an empty chain, and application code is referring to the EmptyChain instance as the head of the collection. And now we have a new link pointing to itself. After the #become: call, the previous link (or application code) now points to the new link, rather than the empty chain. But we also want the new link to have a nextLink that points to the original EmptyChain. Since the #become: is two way, the new link's reference to itself, is now referencing the terminating EmptyChain.
Chain #removeKey:
John Brant and Don Roberts once shared this riddle with me. "How do you delete a single link in the linked list with a pointer only to the link you want to delete?" The apparent conundrum, is that without knowing what the previous link was, how do you update its nextLink pointer to reference the nextLink of the link to be deleted. The answer is, that you don't. Instead, what you do is turn yourself (the link to be deleted) into the next link by copying its key and value to yourself, and then updating your nextLink to the be nextLink of what you just copied. So in essence what you do, is turn yourself into a clone of the next link, and then remove the now redundant nextLink from the link chain.
This ends up being a polymorphic implementation of a private method called used to #replace: aPreviousKey. The Chain implementation is easy enough:
replace: aPreviousLink
aPreviousLink setKey: key value: value next: nextLinkWhen we're removing the last normal link of the Chain though, the one that points to the terminating EmptyChain, that one basically does the reverse of the at:put:, using the self referential link + become: trick to change places.
replace: aPreviousLink
aPreviousLink
loopSelf;
become: selfDoes it Make a Difference?
Chain and EmptyChain were a lot of fun to code up. Where I was interested in Dictionaries of sizes around 10 or less, it was a really fun way to approach the problem. I did go into this wondering about performance though. How does it stack up against normal Dictionary usage? What follows are a series of performance graphs for different dictionary APIs. In most cases I used Symbols, they have the cheapest hash and = implementations, so we don't get lost in worrying about the overhead of those. Most of the charts show results for Dictionary sizes ranging from 1 to 15.
Accessing Methods

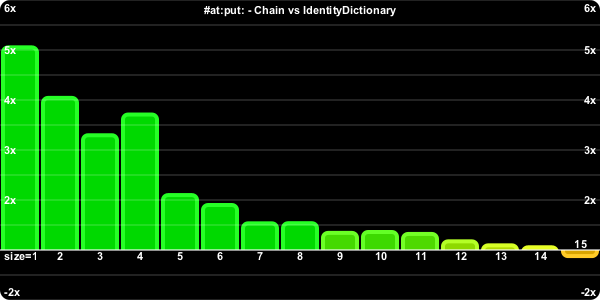

The (positive) indicates that the key was found, or in other words that the exception block was not followed. (negative) indicates the exceptional block was evaluated.
The performance for the negative path deteriorates sooner, because we have to traverse the whole chain to discover it's not there, so it becomes a function of the chain size.



There's a bit of sawtoothing to this chart. It occurs (in part) because these APIs are inherently dependent on the actual Dictionary size, for the Dictionary case. Not reported size, but the amount of memory allocated behind the scenes for a Dictionary of that size. The actual #basicSize of the 1-15 sized Dictionaries is #(3 3 7 7 7 17 17 17 17 17 17 17 37 37 37).




#size is the bane of our singly linked list. For a Dictionary, it's just a return of the tally instance variable. But the Chain has to enumerate all of its links each time to compute the current size. As the chain gets longer, it takes more and more time to compute the size.
Enumerating
I wasn't as exhaustive with this set, I figured by now the picture was becoming clear.




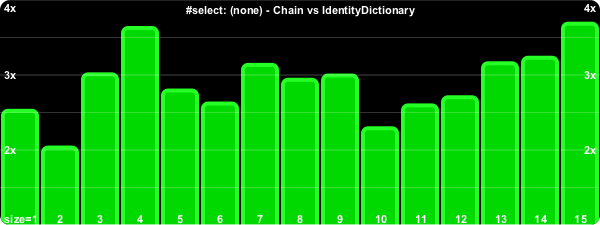


#reject: is the same as #select:.
Removing
Removal is tricky to time. We need full dictionaries to remove from. It's actually the same problem as found with timing the #at:put: of initially new keys. So married the two together by measuring the time it takes to remove an existent key and then add it back.
The Chain pays a heavy price in this one because #at:put:'ing a new item involves allocating a new link, as well using #become: to insert it. As a net, that's a little slower than the IdentityDictionary which doesn't need to allocate each time.
On Beyond Dictionaries
We could do more of the Dictionary APIs, but I think the above charts are more than enough to get the picture. For things like property Dictionaries, where unique keys are determined early on, and the size is usually small, an object like Chain can offer a bit of performance boost (if you've determined you're in a speed crunch; remember "Make it Work. Make it Right. Make it Fast.").
Chain has some other interesting properties though. Unlike Dictionary, Chain can use nil as a key. And unlike Dictionary, order is preserved. At least, the order that you add the initial keys. As a Chain grows, its enumeration order doesn't change. This brings to light an interesting possibility. What if we used a Chain in place of an OrderedSet? We could make something like Chain that left the values out, or just put nil in for the values and simply use the various key APIs. For small OrderedSets we'd likely get a significant speed jump.
Why stop with OrderedSet emulation though. Dictionaries are just generalized Sequences. Or put another way, a Sequence (e.g. Array, OrderedCollection, etc) is just a special kind of Dictionary that limits its keys to a contiguous range of integers starting at 1 and ending at some size. It turns out that making Chain respond to Sequence APIs such as #first, #last, #first:, #last:, #allButFirst:, #allButLast:, #any, #fold:, #reverse, #reverseDo: is a snap.
Want an growable array that can #do faster than an array? Check this out:
In a variety of scenarios, the Chain will actually perform on par or faster with Sequences. Just don't send #size to them.
Other Thoughts
One could do a number of different things past this point. One could make different kinds of Chain subclasses for identity behavior versus equality. The trick one could use is to have the EmptyDictionary know the kind of class to use for normal links.
One could avoid the use the clever #become: trick to add and remove links, by creating private helper methods that the basic APIs called on, passing the necessary state along to do the work without resorting to clever #become: incantations.
One could play with having Chain links that stored more than one key->value pair in fixed instance variables. This would reduce the amount of link traversal via message sends relative to fixed var access, though code complexity would need to increase as it had to deal with partially populated links.
Lastly, one has to keep in mind what this exploration has been about. It's been about using fixed var access in preferences to indexed variables. And in never sending #hash to the keys, sending = only instead. The value of not using the #hash, goes down though as #hash methods get faster while = methods get slower. In other words, if you're keying with objects that have lengthy equality comparisons and fast hash comparisons, the inflection point in size where the Chain technique wins out over a traditional hash approach will shift to the left.
No comments:
Post a Comment